对于XGBoost调参都是一顿瞎调, 然后从Kaggle上fork一个kernel了事. 因为用hyperopt或者是BayesianOptimization 跑出来的参数跟别人的效果差了老多.
XGBoost是在GBDT的基础上改进的, 首先要看GBM的参数是什么意思1.
GBM参数
GBM的参数分为3种:
- 决策树参数: 影响决策树的构建
- 提升方法(Boosting)参数: 影响提升方法的过程
- 杂项: 控制其他部分
下图介绍了一部分参数的含义1
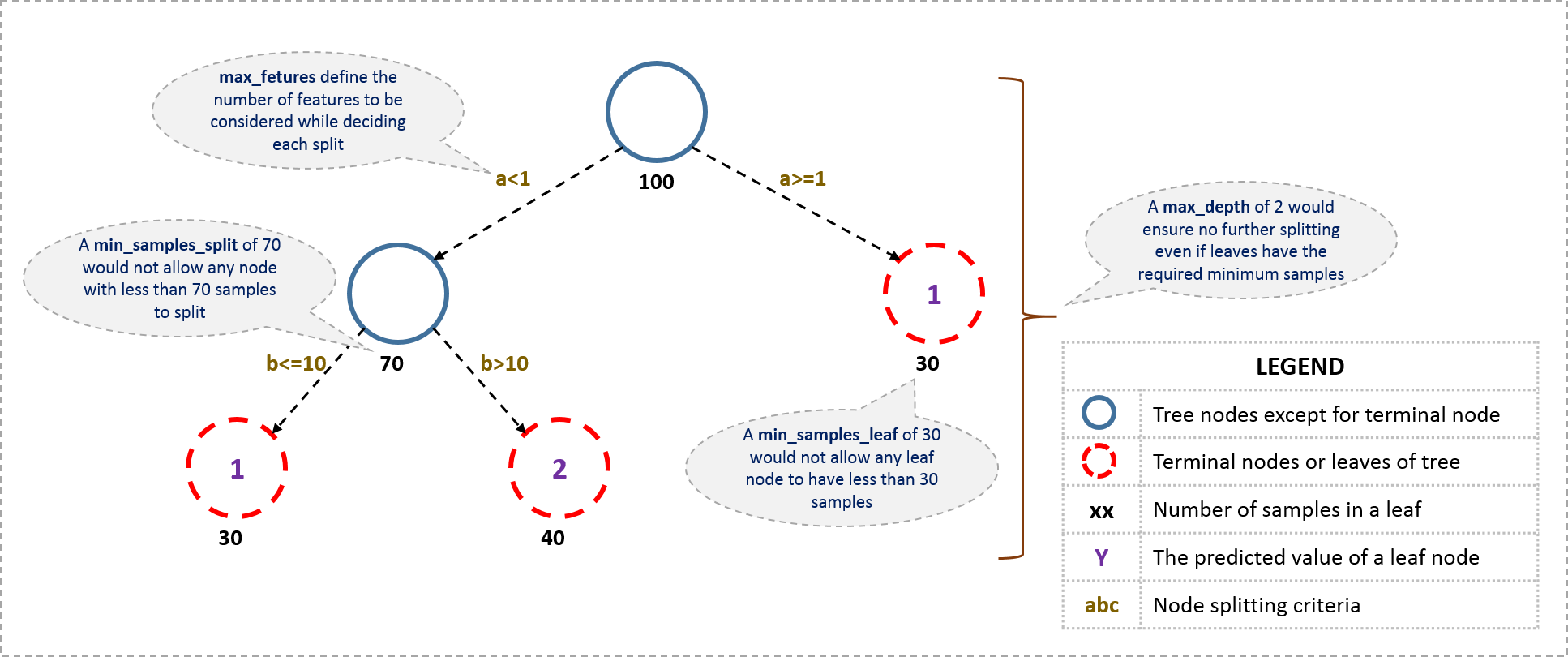
与决策树相关的参数 - Tree-Specific Parameters
min_samples_split- 控制结点可划分时的最少样本数, 样本数少于该值时, 结点不会继续划分.
- 用于控制过拟合, 这个值太大了又会导致欠拟合( 考虑决策树的剪枝过程, 这个参数的作用是十分直观的 )
min_sample_leaf- 控制结点中的最少样本数目, 任何叶节点的样本数都要大于这个值
- 类似于上一个参数, 也可以用于控制过拟合
- 当存在类别不均衡问题时, 应该设为较小的值, 因为类别较少的样本数可能很少
min_weight_fraction_leaf- 类似于上一个参数, 只是表示的形式不同, 这里用总样本数的比例表示最小叶结点样本数
- 该参数与上一个参数只应该定义一个
max_depth- 决策树的最大深度
- 用于控制过拟合( 更深的树 更有可能拟合训练数据)
- 应该使用CV调整
max_leaf_nodes- 最大叶结点数目
- 可以用于替代上一个参数, 深度为n的二叉树叶结点的数目为2^n.
- 如果定义该参数, 上一个参数将会被忽略
max_features- 划分结点时最多选择的特征数目( 考虑一下随机森林的情况, 每次只选择一部分特征用于构建划分结点)
- 总特征数目的均方根是较好的选择, 但是应该考虑到特征数量的30%~40%
与提升方法相关的参数 - Boosting Parameters
提升方法的一个伪码
1. 初始化基分类器
2. 从1迭代到n_estimators
2.1 根据前一次预测, 更新样本权值
2.2 在样本上训练模型
2.3 在所有样本上进行预测
2.4 更新基分类器的线性组合, 考虑learning rate
3. 返回基分类器的线性组合
其中涉及到的参数有
learning rate- 在Boosting方法中, 根据基分类器的错误率, 已经会给每一个基分类器指定一个权重. 这里再加一个learning rate, 应该是在这个权重的基础上再加上一个衰减因子. (我记得在kaggle的讨论区看过. 但是一时找不到了)
- 更低的lr会增加模型的泛化能力, 但是同时也要求要更多的树.
n_estimators- 树的数量/Boosting迭代次数 (难以想象半年前我不知道树的数量跟迭代次数有什么关系, 太弱鸡)
- 树的数量太多也可能会过拟合, 因此也需要用CV去调整
subsample- 训练每棵树时使用的样本比例. 即训练时对数据随机采样, 获取指定比例大小的数据集.
- 0.8 通常较好, 但是可以进一步调整.
杂项参数 - Miscellaneous Parameters
除此之外, 还有一些其他参数控制
loss- 控制损失函数的类型, 分类或是回归
init- GBM的初始值, (统计学习方法P147)
random_state- 涉及到随机时都会有的参数, 铁定是42
verbose- 控制模型啰嗦的程度, 值越大话越多.
warm_start- 是否在训练前先使用一棵树拟合训练集.
接下来是干瞪眼时刻, 说这些, 虽然知道参数是什么意思, 咋调啊 o.O

对于LR来说, 越低越好, 同时要有足够数量的决策树. 但是当LR很小, 决策树很多时, 计算量要求也很大.
- 选择相对较大的lr, 默认的0.1, 对于不同的问题, 0.05~0.2都是可以的.
- 确定对应当前学习率最优的决策树数量.
- 调整决策树相关的参数
- 降低学习率, 同时增加决策树的数量.
剩下的调整过程参见1, 就是粗暴地GridSearchCV.
注意第4步, 在降低学习率的同时应该增加树的数量, 如果CV效果下降, 说明树的数量增加得不够.
XGBoost 参数2
XGBoost的优点
- 引入正则化, 降低过拟合
- 并行处理. (生成树的过程仍然是串行的, 但是构建树的内部过程可以并行)
- 高度灵活, 可以自定义损失函数和评价指标
- 内建处理缺失值的方式, XGBoost对缺失值指定了默认的划分方向, 这种划分是由学习得来的.
- 剪枝处理, XGBoost分裂到最大深度后对树进行剪枝.
- 内建CV
XGBoost参数分为3类:
- 一般参数
- Booster参数, 控制每个booster
- 任务参数
一般参数
booster[default=gbtree]- booster的类型
- gbtree: 树模型
- gblinear: 线性模型
- booster的类型
slient- 设为1时, 模型就比较自闭, 不爱说话
- nthread
- 线程数, 默认为机器的线程数量
Booster 参数
这里只考虑gbtree的参数
eta[defaul=0.3]- 学习率/衰减因子
min_child_weight[default=1]- 子结点中的最小样本权重和
- 类似于GBM中的
min_child_leaf(啥, 原文写的是这个, 我觉得应该是min_sample_leaf). - 控制模型过拟合程度, 大偏向于欠拟合, 小偏向于过拟合
max_depth[default=6]- 决策树的最大深度
- 过大偏向过拟合, 过小偏向欠拟合
max_leaf_nodes- 最大叶子结点数量, 与
max_depth类似
- 最大叶子结点数量, 与
gamma[default=0]- gamma控制在结点分裂时的最小增益量( 类似于决策树中的熵增或增益率)
max_delta_step[defalut=0]- 没看懂, 不用管
subsample[default=1]- 训练每棵树时的样本采样比例.
colsample_bytree[default=1]- 特征采样的比例, 类比随机森林
colsample_bylevel[default=1]- 每层上特征采样比例, 没看懂跟上一个参数有什么关系
lambda[default=1]- L2正则项的权重
alpha[default=0]- L1正则项的权重
scale_pos_weight[default=1]- 当类别极度不均衡时, 这个参数设为大于0的数, 帮助更快收敛
Task Parameters
objective[default=reg:linear]- 损失函数
- binary: logistic
- multi: softmax
- multi: softprob
- 损失函数
eval_metric[default according to objective]- 验证数据上使用的评价指标
- 回归任务默认为rmse. 分类任务默认error
- 常用的值
- rmse
- mae
- logloss
- error, 二分类错误率
- merror, 多分类错误率
- mlogloss
- auc
seed- 随机数种子, 钦定42
调整过程
- 选择相对较高的学习率, (0.1), 确定对应的最优决策树数量
- 调整树相关的参数, (depth, child_weight, gamma, subsample)
- 调整正则项参数(lambda ,alpha)
- 降低学习率, 同时增加决策树的数量
剩下的参见2. 又是GridSearchCV.
总结
虽然知道参数啥意思, 但是就GridSearchCV吗, 太暴力了.

Comments !